Neural Networks and Recurrent Neural Networks (RNN)
- pencil27 Oct 2021
- clock6 min read

The neural network is a very popular machine learning algorithm that has gained enormous traction with the introduction of deep learning. It is no accident that the algorithm is named as such, as its behaviour resembles that of the biological neural networks that make up the brain network responsible for human’s intelligence and our ability to think.
The idea of the neural network predates deep learning. Introduced by Alan Turing in 1948, the neural network has since evolved greatly and developed many variants to serve different specific tasks, such as convolutional neural networks for image processing and recurrent neural networks for signal processing.
This post aims to:
- describe the basic neural network - dense neural network (DNN)
- address its lack of capability to model sequential data
- describe the recurrent neural network and how it is better at modelling sequential data than the DNN.
Dense Neural Networks
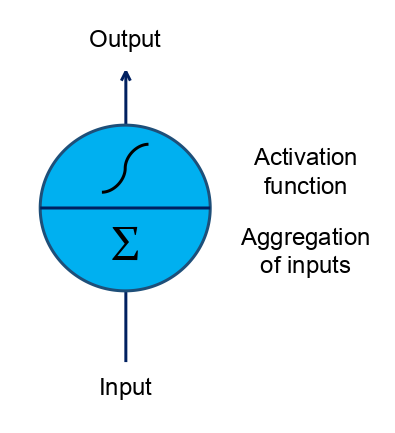
The figure above shows a basic neural network unit - a neuron.
Neuron
In a neuron, inputs are linearly combined using a set of weights and a bias. Mathematically,
where $y$ is the output value, $x_d$'s are the input values, $a_d$'s are the weights and $b$ is the bias.
This simple linear equation forms the basis of a neuron. Input values are linearly combined to produce a prediction on the actual output value. It is effectively a $D$-dimensional linear regression problem.
Its ability, however, is limited to modelling linear relationships between the inputs and outputs. To allow for more complex mapping, the aggregated input is often passed through an activation function before generating the prediction for the output. The activation function is typically a non-linear function to introduce non-linearity into the modelling, such as a sigmoid function, a hyperbolic tangent function etc. The choice of the activation functions also often depends on the task at hand.
Mathematicaly,
where $\phi(\cdot)$ is the activation function.
The same set of input values can pass through multiple neurons, each with different weights and biases, producing multiple outputs. The outputs can be aggregated to a single value through a neuron or simply presented as a multi-dimensional vector, where the length of the vector is the number of neurons. This network of neurons is called a perceptron. The figure below shows a perceptron that comprises three neurons.
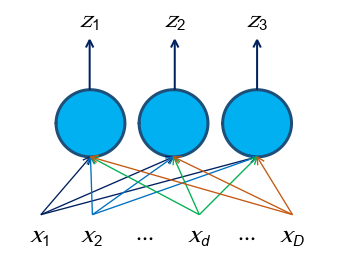
With multiple neurons working together, the modelling power is stronger than just a single neuron, allowing for even more complex mappings.
Furthermore, perceptrons can be stacked on top of each other. This is done by treating the outputs of a perceptron as the input values for another perceptron. This is known as a dense neural network.
In neural networks, the weights and biases are learned through optimisation. This means that the weights and biases are chosen such that the prediction of the output is the optimum. Due to the layers of neurons and complexity of the modelling, the optimisation of the weights is not a trivial problem. The most popular method for optimisation of weights in neural networks is gradient descent with error backpropagation. You can learn more about this optimisation algorithm in the original paper if you are interested, but the basic idea behind this is to optimise the weights by reducing the error of the prediction iteratively.
Limitations
A dense neural network, although powerful, is not capable of accurately modelling sequential data like a time-series. This is because a DNN treats each new set of input values ($x_{1:D}$) as being independent to all the other input value sets in the time-series and thus does not have the notion of order and time. It is therefore not reliable for sequential data like text in an essay, notes in a piece of music, sensor data over time etc. In order to model a sequence, the network needs to be able to understand the concept of order and causality, and somehow 'remember' what happened in the past.
Imagine a sequence of data collected from a sensor over time. A DNN treats each data point as independent, as it assumes that every data point in the sequence has no correlation with one another, which we know is not true.
Recurrent Neural Network (RNN)
Recurrent neural networks (RNN) have special structures implemented into each neuron that allow the network to “remember” previous data points and use them to help with the modelling of the current data point in a sequence of data. Some of these structures include hidden values that enable the model to memorise what has happened in the past, and various gate mechanisms to more efficiently combine past information and new information. Therefore, an RNN is more suitable for handling a sequence-to-sequence mapping.
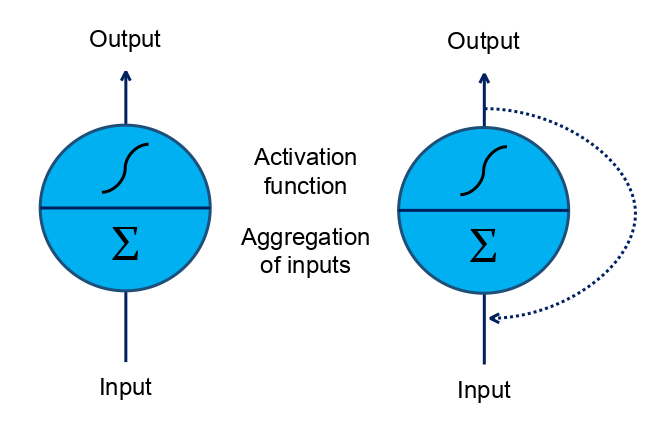
The figure above shows the neuron (on the left) and a basic recurrent neural network unit - recurrent neuron (on the right).
The recurrent neuron is conceptually similar to a simple neuron except that it has a feedback loop from the output to the input. That is, the output from the previous data point is aggregated with the new input data to make the prediction.
Just like in dense neural networks, multiple recurrent neurons can work together and be stacked up into layers to form the recurrent neural network.
There are many variants to the recurrent neural network that involve adding more features to the basic recurrent neuron to strengthen its sequential modelling capabilities. To learn more about recurrent neural networks and its variants, you can visit this post. Here you will find a mathematical description of the RNN and its most common variants.
Conclusion
- The neural network is one of the most powerful modelling tool.
- The basic unit of a neural network is a neuron, which is a simple linear combination of inputs passed through an activation function.
- The dense neural network, though powerful, is not useful for sequential data modelling due to its assumption of independence between data points.
- The recurrent neural network models sequential data more effectively with the help of a feedback loop and other additional features in its neurons.
Author: Chia Jing Heng (andreusjh99)
